Hybrid Cloud Patterns
Hybrid Cloud Patterns and the downstream Validated Patterns are a natural progression from reference architectures with additional value. Here is a brief video to explain what patterns are all about:

This effort is focused on customer solutions that involve multiple Red Hat products. The patterns include one or more applications that are based on successfully deployed customer examples. Example application code is provided as a demonstration, along with the various open source projects and Red Hat products required to for the deployment to work. Users can then modify the pattern for their own specific application.
How do we select and produce a pattern? We look for novel customer use cases, obtain an open source demonstration of the use case, validate the pattern with its components with the relevant product engineering teams, and create GitOps based automation to make them easily repeatable and extendable.
The automation also enables the solution to be added to Continuous Integration (CI), with triggers for new product versions (including betas), so that we can proactively find and fix breakage and avoid bit-rot.
Who should use these patterns?
It is recommended that architects or advanced developers with knowledge of Kubernetes and Red Hat OpenShift Container Platform use these patterns. There are advanced Cloud Native concepts and projects deployed as part of the pattern framework. These include, but are not limited to, OpenShift Gitops (ArgoCD), Advanced Cluster Management (Open Cluster Management), and OpenShift Pipelines (Tekton)
General Structure
All patterns assume an OpenShift cluster is available to deploy the application(s) that are part of the pattern. If you do not have an OpenShift cluster, you can use cloud.redhat.com.
The documentation will use the oc command syntax but kubectl can be used interchangeably. For each deployment it is assumed that the user is logged into a cluster using the oc login command or by exporting the KUBECONFIG path.
The diagram below outlines the general deployment flow of a datacenter application.
But first the user must create a fork of the pattern repository. This allows changes to be made to operational elements (configurations etc.) and to application code that can then be successfully made to the forked repository for DevOps continuous integration (CI). Clone the directory to your laptop/desktop. Future changes can be pushed to your fork.
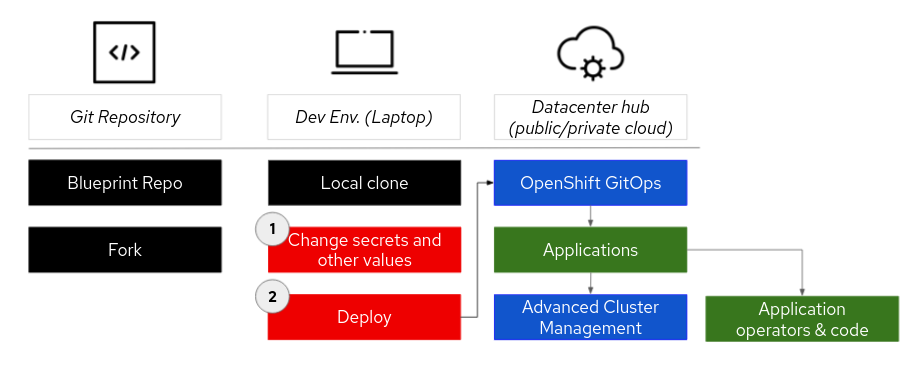
Make a copy of the values file. There may be one or more values files. E.g.
values-global.yamland/orvalues-datacenter.yaml. While most of these values allow you to specify subscriptions, operators, applications and other application specifics, there are also secrets which may include encrypted keys or user IDs and passwords. It is important that you make a copy and do not push your personal values file to a repository accessible to others!Deploy the application as specified by the pattern. This may include a Helm command (
helm install) or a make command (make deploy).
When the workload is deployed the pattern first deploys OpenShift GitOps. OpenShift GitOps will then take over and make sure that all application and the components of the pattern are deployed. This includes required operators and application code.
Most patterns will have an Advanced Cluster Management operator deployed so that multi-cluster deployments can be managed.
Edge Patterns
Some patterns include both a data center and one or more edge clusters. The diagram below outlines the general deployment flow of applications on an edge application. The edge OpenShift cluster is often deployed on a smaller cluster than the datacenter. Sometimes this might be a three node cluster that allows workloads to be deployed on the master nodes. The edge cluster might be a single node cluster (SN0). It might be deployed on bare metal, on local virtual machines or in a public/private cloud. Provision the cluster (see above)
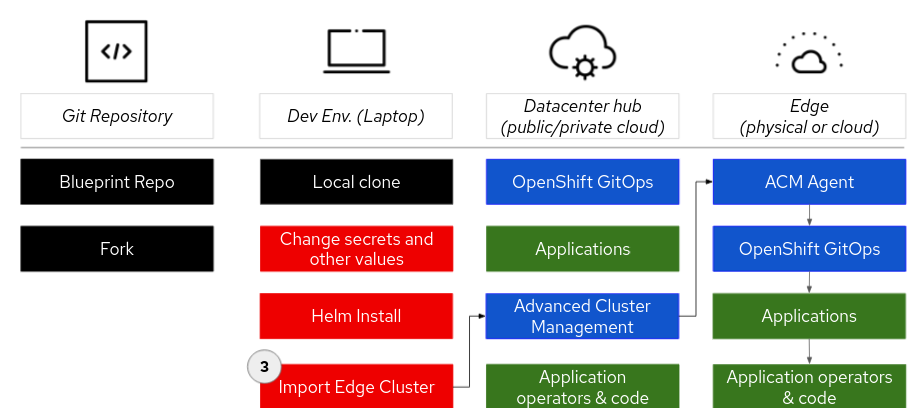
- Import/join the cluster to the hub/data center. Instructions for importing the cluster can be found [here]. You’re done.
When the cluster is imported, ACM on the datacenter will deploy an ACM agent and agent-addon pod into the edge cluster. Once installed and running ACM will then deploy OpenShift GitOps onto the cluster. Then OpenShift GitOps will deploy whatever applications are required for that cluster based on a label.
OpenShift GitOps (a.k.a ArgoCD)
When OpenShift GitOps is deployed and running in a cluster (datacenter or edge) you can launch its console by choosing ArgoCD in the upper left part of the OpenShift Console (TO-DO whenry to add an image and clearer instructions here)
